
2025年3月27日,领邦智能董事长崔忠伟博士应邀参加VisionChina2025(上海)机器视觉展暨机器视觉技术及工业应用研讨会,并发表《视觉检测大模型及智能体》主题演讲,下文根据崔忠伟先生的主题演讲内容整理而成。
大家好,
非常感谢大家起这么早来听今天的第一场演讲,我一定努力给大家带来一些精彩的内容。我今天汇报的题目是视觉检测大模型及智能体。那么,什么是大模型呢?春节期间,大家都被DeepSeek科普了一番,所以这里我就不再赘述了,只强调几个关键要点。我们讲的大模型不是大家熟悉的大语言模型(Language Model, LM),而是大世界模型(World Model, WM)。LM主要是对自然语言的理解与生成,基础是对概念的理解;而WM则是对世界的理解与生成,基础是对像素或体素的理解。另外,LM模型采用的是Transformer结构,而不是视觉领域传统的卷积CNN结构,这一点大家应该都了解。在这里,我们只研究大世界模型(WM)中的检测类任务,暂时不涉及生成任务。
1.视觉检测大模型
我们去用一个传感器来探测世界,判断这个世界里面有什么目标和目标之间的相互关系及目标和背景的相互关系,这就是检测类WM的定义。为什么我们能做这个?是因为我们有数据,领邦智能有海量的工业缺陷数据。这个模型再强调一下,它是单模态的。为什么不是多模态?因为我们用文本、用语言去指示一个工业缺陷或工业目标,其实是说不清的,我们叫做目标的描述和指向性不强。所以它是单模态的,缺陷还是需要像素级标注一下。这是给大家做一个大模型的导入。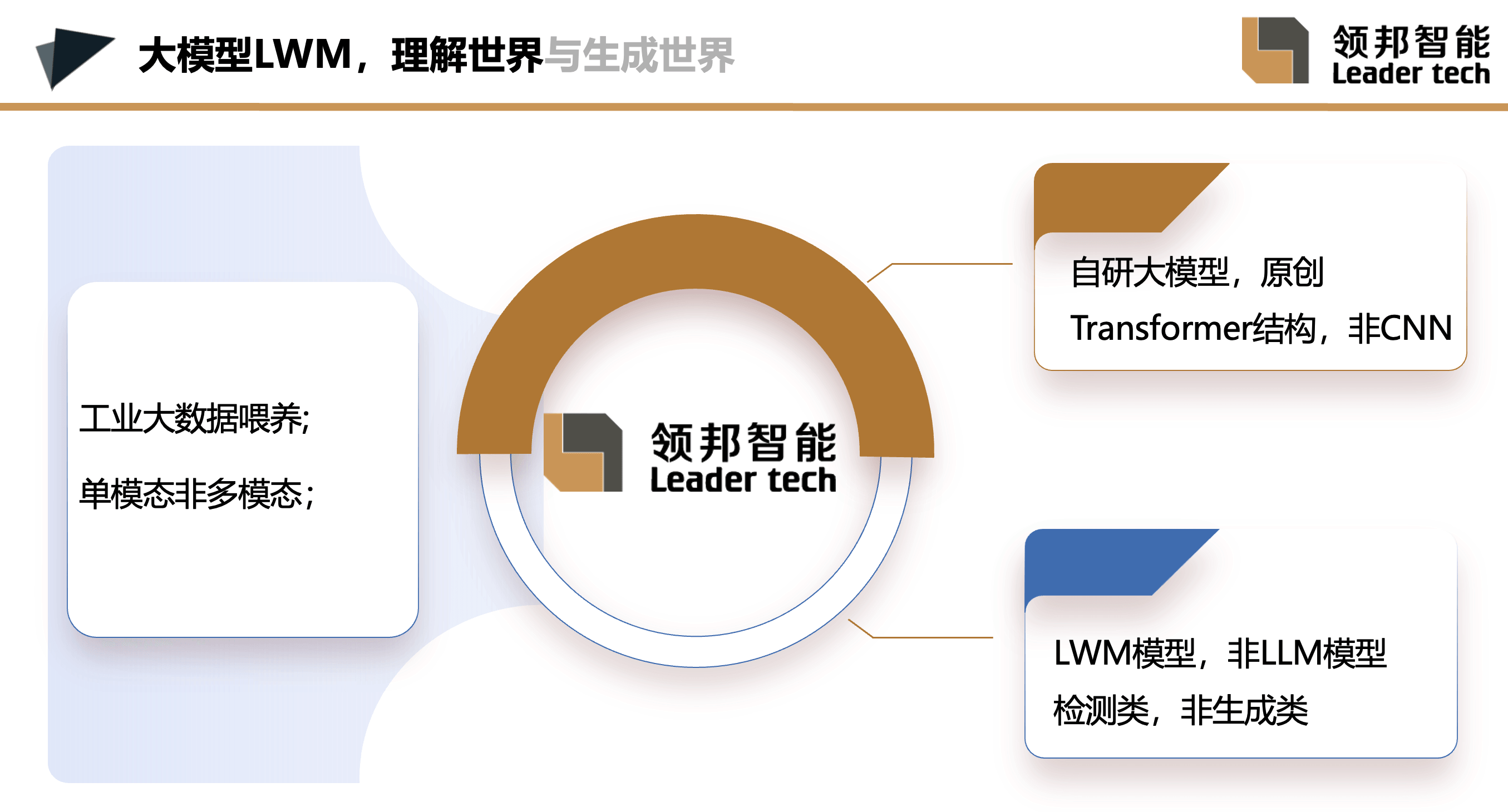
我们大模型针对的任务是机器视觉市场,机器视觉市场大家都知道分为部件和设备,还包括软件。我们机器视觉行业最特殊的是软件的占比非常高。可以用两句话简单描述一下市场现状:第一,视觉技术就像扳手一样,已经广泛地应用于工业车间。这个市场容量是千亿级别的,甚至是万亿级别的,市场潜力巨大。第二,市场上有2000多家供应商,其实大家都知道工业领域2000多家企业还是过多了,过散过碎了。原因是什么?其实底层逻辑只有一个,缺乏通用的生产力,也就是我们视觉行业严重不通用,导致各家都在作项目,产品化业务不多。
具体来说,有两大不通用:第一是工业成像不通用,基本上要凭经验靠器材去实验;第二是后续处理软件不通用。如果视觉行业能从2000家缩小到200家,那么这个行业就健康了,这需要通用的生产力推动。
领邦智能的贡献,是把图像的后处理软件做通用了,也就是我们所说的视觉检测大模型。从大模型时代开始,相当于瓦特改进后的蒸汽机,而过去的小模型时代,就类似于瓦特之前的蒸汽机。这是一次重大的通用生产力变革。我们通过下面这张图来直观地比较一下大模型时代和小模型时代,下面这张图特别直观,建议大家都拍下来研究一下。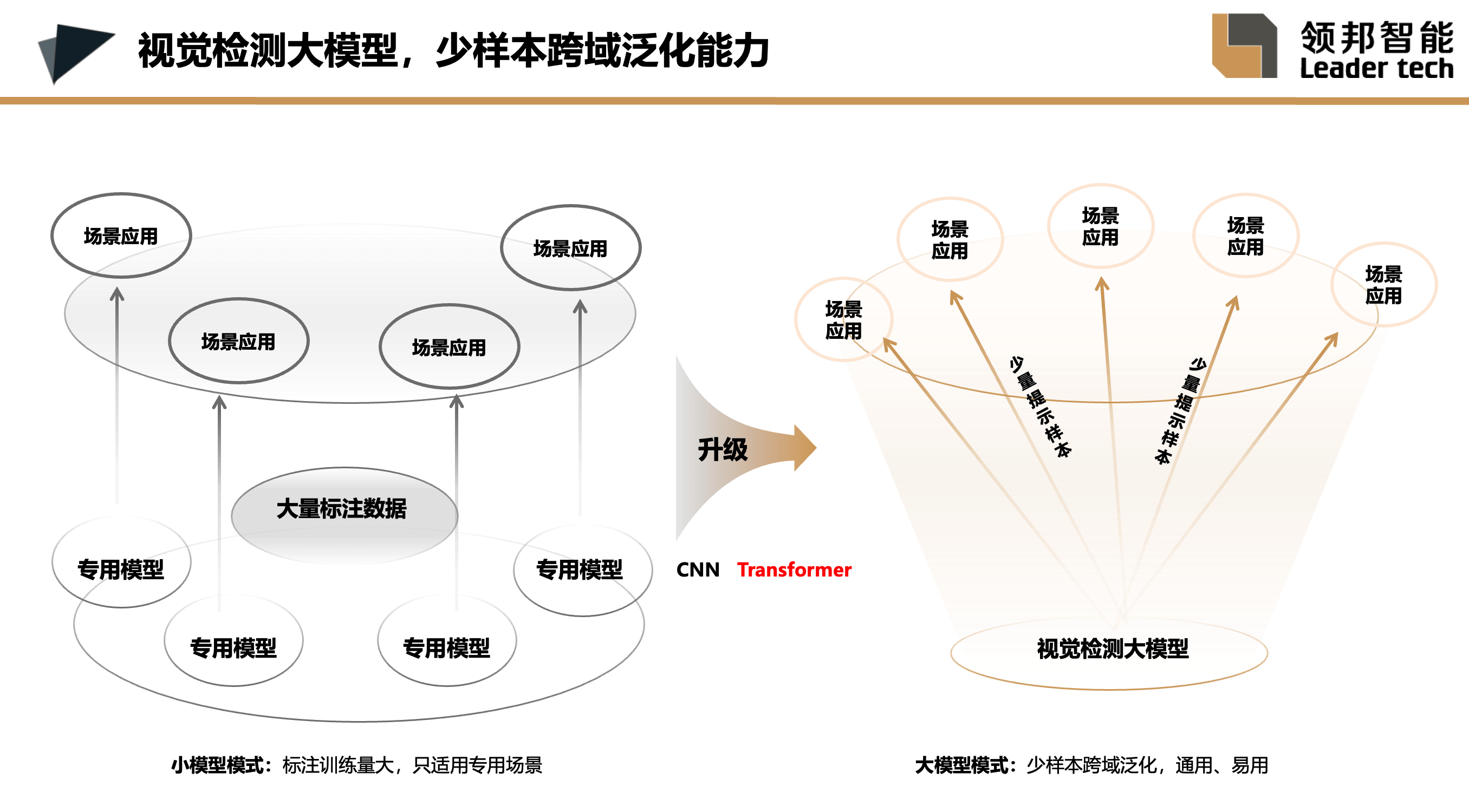
过去的小模型通常都是专用的,每当有一个具体的任务场景时,我们需要收集几百张甚至上千张的数据进行标注和训练,训练通常也要依赖云端。这种模型最大的弊端是不通用,一旦更换任务,就必须重新训练。即便是同一个任务,可能三个月后生产线的工艺发生了变化,这个模型仍然无法通用,又得重新训练,因此标注和训练的成本非常高,大概占乙方企业收入的10%,这对企业来说是个相当大的成本。这也导致行业内经常出现标注和训练到底该由甲方还是乙方来做的争论。
现在,领邦智能研发了视觉检测大模型,属于机器视觉的基础模型(FM),泛化能力非常好,只需少量的提示样本,即可迁移到具体的视觉检测任务上(如上图右所示)。大家在看类似的图时,通常会看到在基础模型与任务之间插入行业模型(如PCB行业模型、玻璃行业模型),但为什么在大模型中却不需要行业模型呢?这是因为基础模型本身的泛化性能已经非常强大,每类缺陷只需提供少量的提示样本(比如1-5张)就可以满足检测要求,因此行业模型失去了存在的必要性。领邦智能的视觉检测大模型已经达到这样的程度,具备类人的特征。与人类非常相似,处理具体任务时只需要很少的提示样本即可快速完成任务。举个例子,人类在进行工业质检时,往往只需观察几个样本,就能轻松掌握任务要求,因此大模型同样具备这种能力,这也正是基础模型直接对接具体任务的优势。以往的视觉检测主流技术通常采用卷积结构,而我们现在采用的是更先进的Transformer结构。当模型规模达到10+亿参数后,就会产生智能涌现现象,泛化性能就能达到理想的状态。
大模型的关键并不在于大小,而在于大规模的预训练。目前还有一种使用卷积CNN进行预训练的方法,但CNN本身无法像基于Transformer的方法那样从大规模预训练中获益。这种方法所训练出的模型由于泛化性能不足,只能勉强算作行业模型,无法达到基础模型的要求。“预训练概念及方法”明显属于Transformer时代,而非传统的CNN卷积时代。在当前技术条件下,基于CNN进行预训练不仅没有必要,而且泛化性效果也难以令人满意。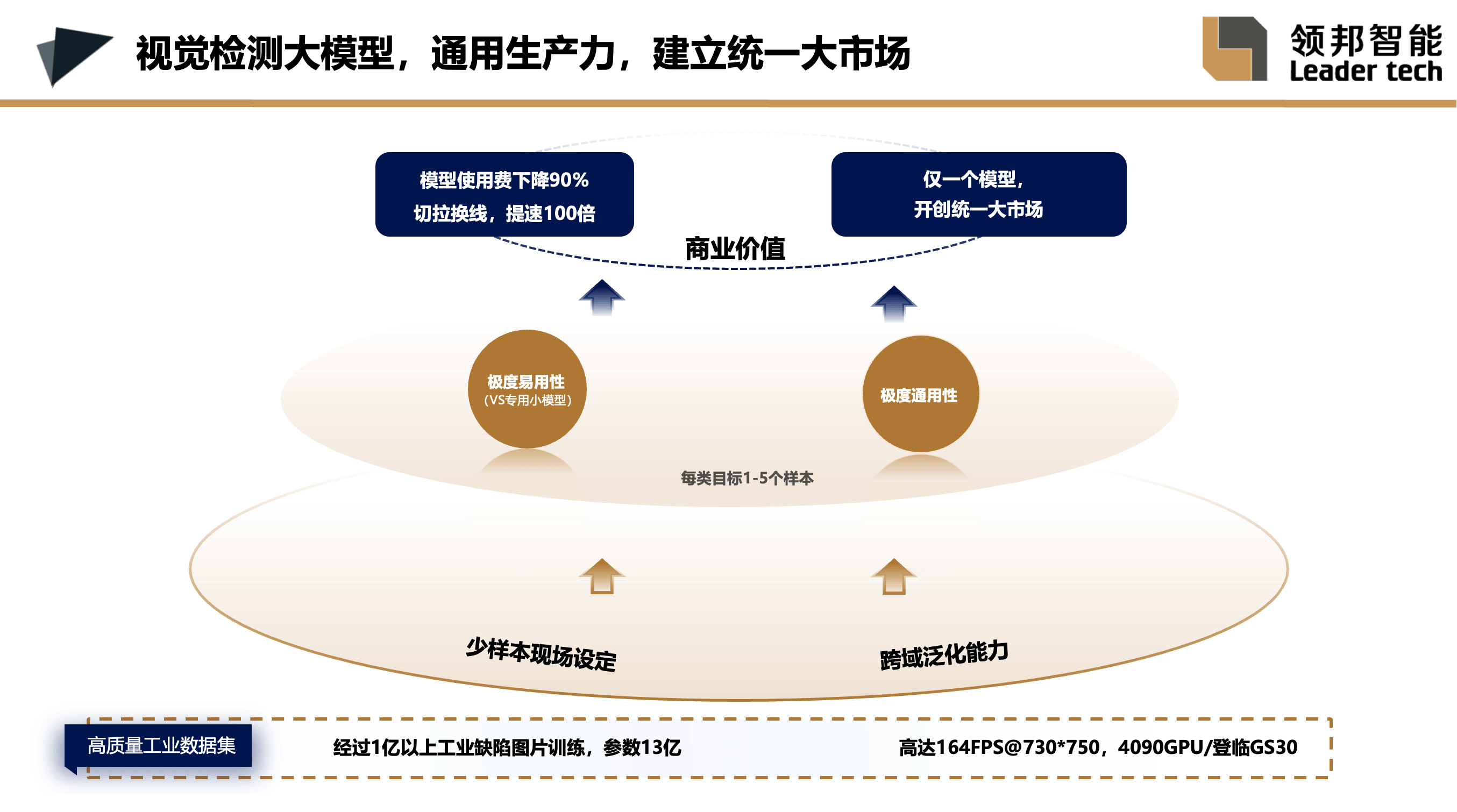
大家可能会疑问,这么大的模型运行速度会不会很慢?实际上并不会慢,比如在4090显卡上,我们可以达到每秒处理150+张图片的速度,这个速度是非常快的。从实际应用的角度来看,大模型的价值主要体现在两个方面:
第一,是现场设定的少样本需求。在具体任务中,只需要很少的样本,通常每类缺陷或每类目标提供1-5张图片即可完成模型的搭建。不仅仅是检测缺陷,还包括监控人的操作过程是否存在错误,也就是过程监控。以及装配确认,即确认装配是否出现了错漏反。
第二,是跨领域的泛化能力。它能跨越众多垂直行业,用一个通用的生产力将整个视觉行业统一起来。
也正是这两大特点,使得大模型具备极强的易用性和通用性。仅需标注少量样本,几分钟内就能快速搭建,非常便捷;通用性体现在能够打通各个垂直行业的应用壁垒,大大降低了模型的使用成本。
此外,大模型的适应性特别强,能够快速切换规格。举个例子,一些大型制造企业可能每两天就要更换一次规格,以前的小模型技术无论怎么调整都很难快速适应,但大模型却能快速地适应这种频繁变化。
另外,这项技术对整个市场还有一个重要的意义,那就是一个大模型就能够推动行业集中化,使行业不再碎片化,从而避免频繁地重复开展类似项目。因此,我们可以说,这项技术是彻底的颠覆性创新,而非简单的技术改进。
或许有人会疑问,小模型是不是在某些特定场景下更有优势?是不是有些事情小模型能做得更好,而大模型却做不到?答案非常明确,没有这样的情况存在。并不存在大模型和小模型各有所长的情况,实际上大模型已经完全取代了小模型的作用,这一点我们必须非常明确地强调。
总之,这是一项彻底颠覆性的技术变革,不存在某些任务只有小模型能够完成而大模型却无法做到的情况。两者之间唯一的关系,就是大模型对小模型的完全替代。
我们来看一个视频,用以说明大模型的跨领域泛化能力。
这是一个开源的铁丝网缺陷数据集。根据人类的主观判断,缺陷被分为5类。我们从中每类选取5张NG样本,再加1张OK样本,共计6张图片用于迁移学习。需要特别强调的是,这个数据集对模型来说是完全陌生的——在模型的训练阶段,从未接触过这些图像。视频左侧展示的是模型对缺陷的检测效果,右侧是原图。仅凭这6张样本,模型就完成了对缺陷目标的高精度检测任务。特别指出,这是一种基于像素分割的检测方式,而非方框回归式目标检测。像素分割方式具有更强的通用性,适用于所有类型的检测任务。
2.视觉智能体
为了进一步推动大模型的落地应用,领邦智能研发团队以自主研发的Transformer视觉检测大模型为基础,发挥其卓越的泛化能力,打造了一款融合软硬件的视觉智能体。这款智能体以“通用、易用”为核心理念,集成了包含CPU和GPU的高性能硬件平台以及一套通用的软件系统,将感知(视觉)、大脑(AI决策)和执行(控制)有机结合,极大简化了用户现场部署和使用的复杂度,并成功入选2024机器视觉创新产品TOP10榜单。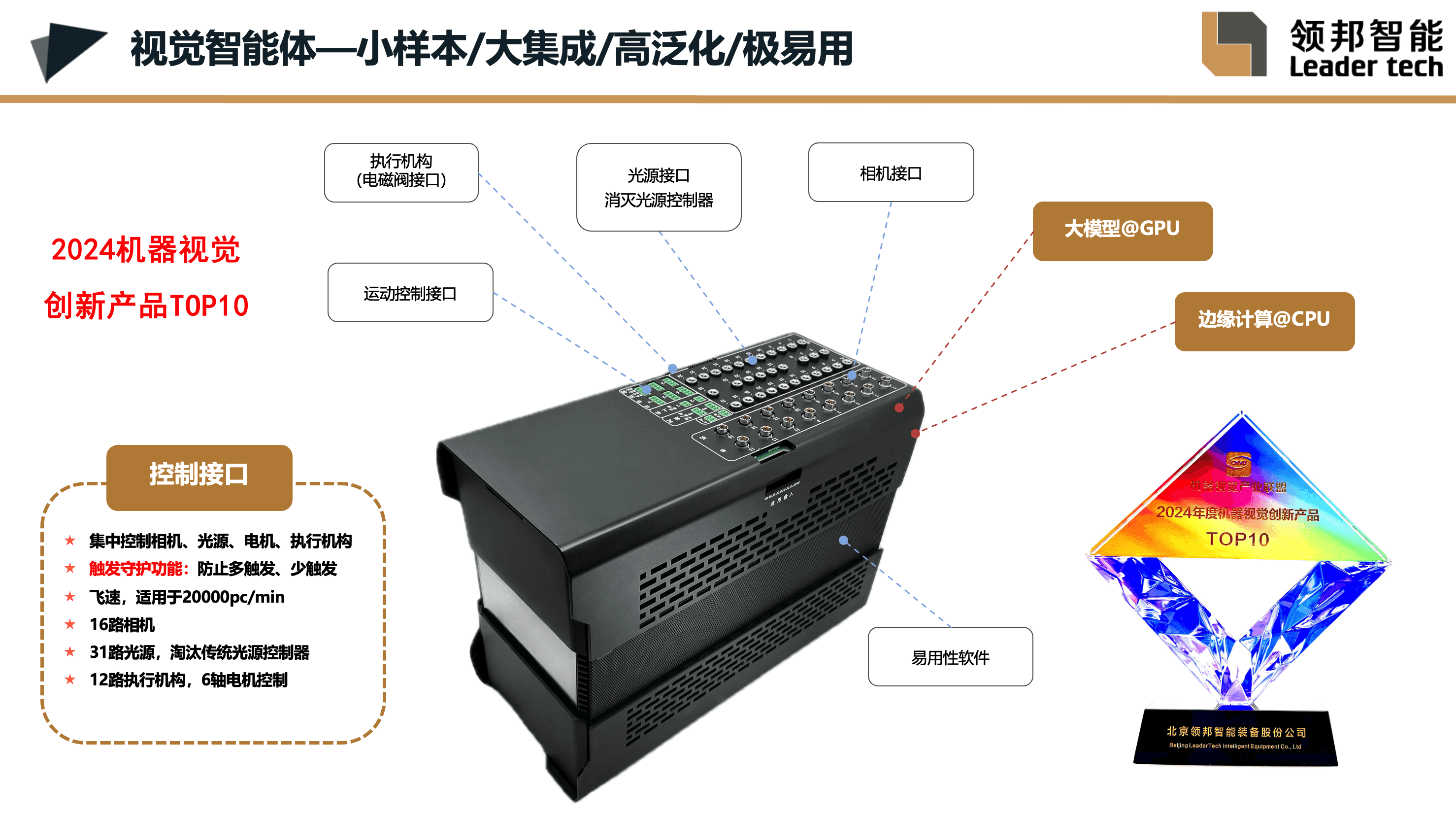
领邦智能此次重磅展出的核心产品——视觉智能体,具有下述特点
少样本快速建模:邦智能自主研发Transformer视觉检测大模型(LWM),突破传统深度学习技术高度依赖大量标注样本的瓶颈,仅需每类1-5张提示样本,即可完成高精度视觉检测模型的快速构建和现场部署,极大降低了工业场景模型开发的门槛和成本。
All-in-One大集成:创新性采用一体化智能架构设计,高度集成16路相机、31路直连LED光源与12路执行机构和6轴电机控制,以将机柜压缩成一台智能体的颠覆式创新,彻底告别传统机柜式部署模式,实现高达150+FPS的高速实时检测能力。该智能体方案广泛适用于工业质检、装配确认、过程监控等多种场景,真正实现工业现场即插即用,部署极简。
值得一提的是,我们完全取消了传统的光源控制器,用户可以直接连接LED光源,无需额外驱动器。
视觉行业高泛化:依托视觉检测大模型(LWM)的强泛化能力,领邦智能突破了传统视觉模型“单任务、单场景”的应用边界,率先实现跨任务、跨场景、跨垂类的通用化部署路径。仅依赖一个通用型视觉检测基础大模型(无需为特定垂类单独训练专属模型,如PCB行业模型),即可高效覆盖多样化、复杂化的工业检测需求,显著降低模型开发与维护成本,加速工业视觉检测从定制化迈向规模化、标准化与智能化。
极度易用性: 领邦智能将复杂的大模型技术转化为直观易用的软件平台,通过清晰友好的界面和极简的操作流程,使现场人员无需专业背景即可完成模型构建与系统运维。采用创新的“二步配置法”:第一步注册相机、光源等外围硬件,第二步配置多通道任务工作流,快速适配复杂检测场景,实现真正意义上的“人人可用、随时部署”。
支持多工位:一个视觉智能体即可同时服务生产线上的多个工位,常见配置为“1拖3”甚至更多,具体可根据各工位的计算负载灵活调整。以搭载RTX4090 GPU的视觉智能体为例,其吞吐率高达每秒75M像素,一个智能体能够同时高效稳定地支持多个工位运行,极大降低了整体部署成本,充分体现了视觉智能体作为边缘计算设备的经济优势。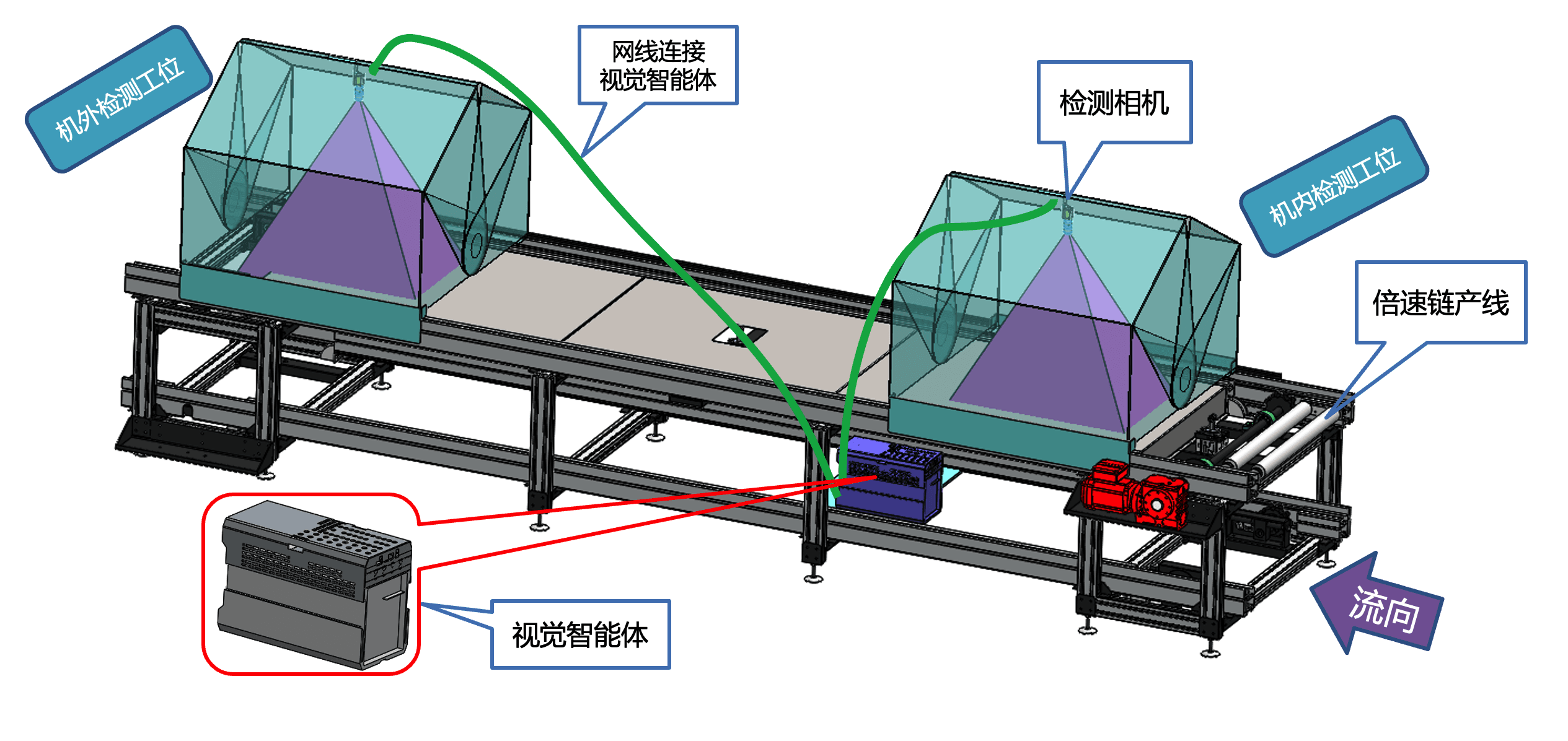
合同前可验证:为了让客户在合同前就能放心购买,领邦智能特别提供现场DEMO演示服务。标准包装箱运抵现场后,两天内即可快速完成系统部署与调试,客户可提前直观验证视觉智能体的实际性能与应用效果。这种“先体验再购买”的模式,在过去卷积小模型时代是无法实现的。
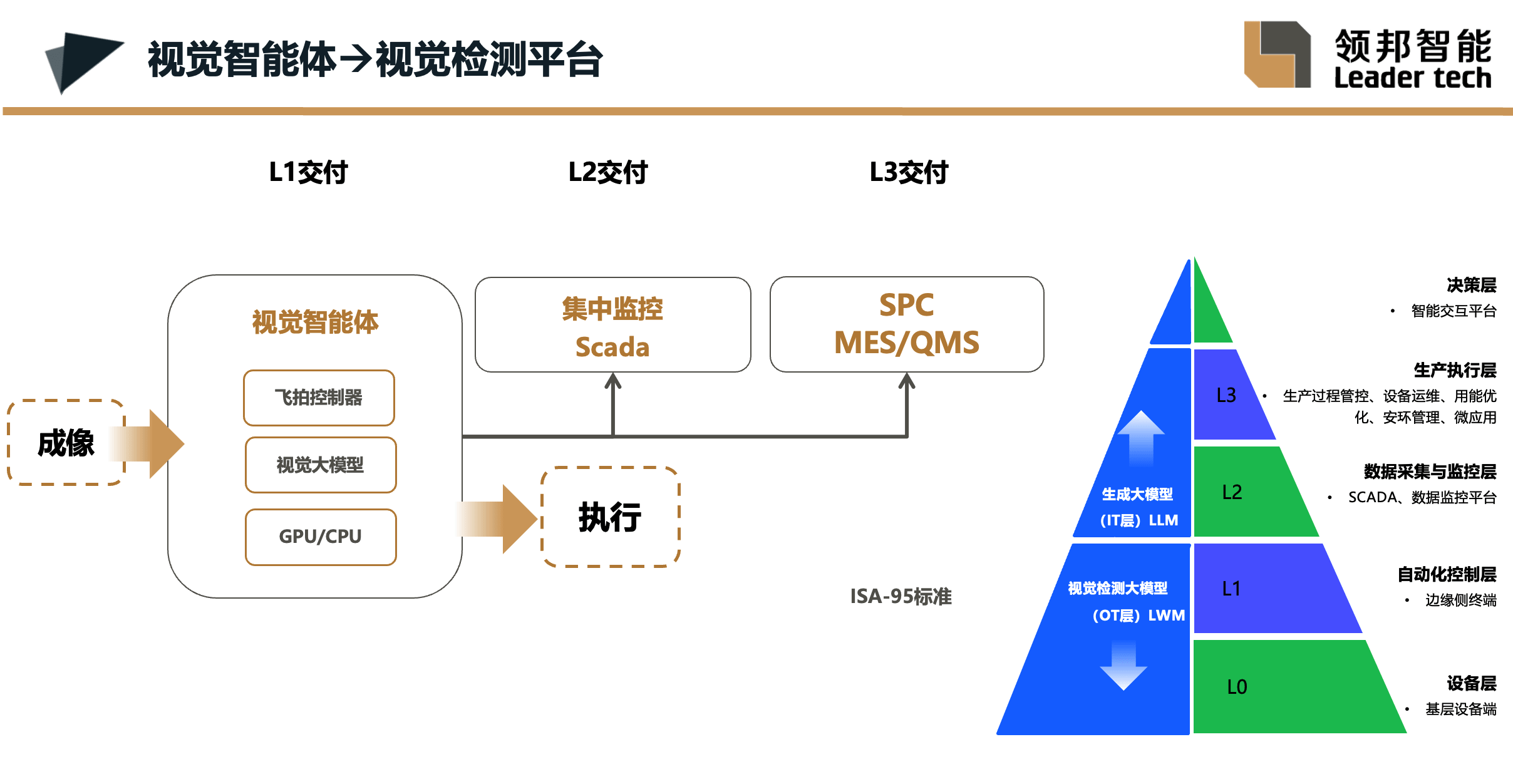
OT/IT融合:领邦智能的视觉智能体不仅能单机运行,还可与企业的IT系统(如L2层SCADA系统和L3层MES、ERP系统)无缝集成。在我们的系统架构中,世界模型(WM)部署于OT层,专注工业现场视觉检测;语言模型(LM)则部署于IT层,负责文本与概念处理以及系统协同。这种清晰的分层架构,体现了领邦智能如何利用大模型技术,推动工厂迈入智能化新时代。
3.颠覆性案例
下面分享一些颠覆性案例,为啥叫颠覆性案例呢?因为确实过去很多案例是根本做不了的,比如过程监控,卷积时代做起来非常困难,但咱们用大模型做却特别容易。
目前领邦智能服务三大产业:工业质检、装配确认,还有过程监控。客户一般分三类:大甲方、大乙方和视觉设备商。其实领邦智能公司的业务跟任何一家视觉企业都是不竞争的。
视觉检测大模型及智能体,正在推动视觉检测行业向小样本、大集成、高泛化、极易用方向快速演进。未来,领邦智能将持续以创新者姿态,积极引领视觉检测技术从定制化走向通用化、普及化,不断赋能全球智能制造产业转型升级。
工业质检领域案例:
电子行业六面体缺陷检测,仅需10+样本,这在卷积模型时代是不可想象的。
轧钢行业缺陷检测,同时精准识别划痕等小缺陷和压痕等大缺陷。
布匹表面质量检测,只使用20张样本即可实现高精度。
手机玻璃盖板缺陷检测,只需14张样本即可完成任务。
汽车压铸铝壳机加面检测,过去卷积模型需要4000张样本,我们只用80张样本便达到同样甚至更高的检测精度。
软包电池缺陷检查,软包电池一般用的是环光源,规格20+种之多。虽然成像条件不是很好,但我们只用了33张样本,其中包括11张合格样本。为啥还得包括11张合格样本?因为良品种类多,但如果是一种规格的话,一个OK样本就足够了,检测效果非常好。
线圈缺陷检测,线圈的成像经常出现偏左偏右的各种状态,我们一共用了168张样本,其中缺陷种类有30多种,还包含了26张合格样本。这里多准备合格样本,意味着它的OK品是复杂多样的。
牙科缺陷检测与评估,牙科检测主要是检查牙齿上的缺陷,并对牙齿的状态进行全面评估。
这些案例应用范围非常广泛,它说明什么问题呢?说明领邦智能的模型有非常强的泛化能力,能在各个垂类场景下泛化。
装配确认领域案例:
打螺丝检查,这种情况,过去用小模型确实特别难解决,但用大模型就很简单了,直接把漏未打的螺丝涂成红色,正常的涂成绿色,迁移训练后,马上投入检测。这里需强调的是,除螺丝孔外,机箱上还有很多“闲孔”,CNN小模型应对这种闲孔会非常困难。
微波炉接线确认,主要是检测这些接线是不是漏装了,这就是典型的装配确认。
洗衣机拧螺丝检查,一共准备了179张数据集,前100张是拧螺丝的,后79张也是拧螺丝的。现在这两张图片就是拧螺丝和没拧螺丝的状态,这个检测主要关注的是四个螺丝是不是漏装了,大家再看看周围还有其他孔洞。
方便面包装线,咱们吃的方便面,料包是不是漏装了,也是装配验证的典型应用。
PCBA打胶检查,PCBA板上有很多高耸的元件,需要打胶加固,需要检出“泄打胶”点位,采用了5张PCBA样本。
前面给大家讲的是装配验证的案例,下面最后再讲一个过程监控的案例。过程监控在卷积时代几乎做不了。
过程监控领域案例:
拧螺丝过程监控,拧满三圈为合格,未满三圈NG,仅用35张样本。
三防漆涂刷监控,我们要监控毛刷的速度。可能有人会觉得监控毛刷的速度还不简单吗?其实还真不简单。因为毛刷对着镜头的形态特别复杂,传统方法可能需要上千张样本才能识别毛刷,而我们的大模型只需要10张样本就能轻松识别。
阀门装配过程监控,阀门的装配是有多个工序的,它存在严格的时序逻辑关系。如果某个地方出错,它就会立刻报警,要求装配工人纠正,仅用30张样本。
检验样品摆放监控,还有一个很重要的场景,就是检验品的摆放,防止工人把OK品和NG品的牌子放错了位置,仅用40张样本。
包装过程监控,包装过程中经常会出现漏装或多装的情况,比如漏装电源线、保险丝、说明书等,仅用35张样本。
附件包装监控,家电产品,往往包括一些附件,这些附件在包装过程中,可能出现漏装、多装等,通过视觉监控,避免质量问题,仅用45张样本,
医疗手术过程监控,识别手术过程中的脉管、淋巴结、手术器械等目标,用于引导手术机器人操作,仅用60张样本。
过程监控,大部分应用是动作监控,就是检测一个动作是否符合SOP的要求。如果动作不符合规定,它就会报警,提示工人及时纠正,纠正后再继续作业。大家都知道,现在的工人不太愿意被训练,目前工人的质量能力2Sigma左右,而通过过程监控技术赋能,可以轻松地帮助工人的质量能力提升到6Sigma(西格玛)水平。
大家从刚才看到的案例可以发现,领邦的视觉检测大模型只要涉及视觉,都能实现跨领域泛化。以前没有出现过这么通用的视觉生产力工具。
最后咱们总结一下,目前领邦智能推出的这个视觉大模型已经非常接近人类的智能水平了。什么意思呢?就像人类学习一个新任务一样,只要给它提供1-5个示范样本,它基本上就能学会了。所以我们强调,这个大模型不仅是少样本的,还是跨领域泛化的,几乎适用于所有的视觉任务。
公司简介
领邦智能成立于2016年,作为一家股份制企业,经过六年积累,构建了涵盖多个场景的真实生产数据体系。自2023年起,公司正式启动大模型训练工作,并于2024年3月30日发布视觉检测大模型iBrain。2024年10月,领邦智能实现视觉智能体的批量生产,标志着大模型在工业场景中的全面落地。公司同时荣获“国家级专精特新小巨人企业”称号。